В релизе ABAP 7.52 стало возможным использование внутренних таблиц как источника данных в ABAP SQL:
|
1 |
SELECT FROM ...@itab AS table_alias... |
Существует два сценария выполнения таких запросов:
- Для выполнения SQL запроса не требуется переноса содержимого внутренней таблицы на уровень СУБД. В таком случае обработка запроса осуществляется непосредственно на сервере приложений, по аналогии с табличным буфером.
- Для выполнения SQL запроса требуется перенести содержимое внутренней таблицы во временную таблицу на уровень СУБД. Этот сценарий поддерживается не всеми СУБД и чтобы статический анализ кода не ругался, следует использовать прагму: ##itab_db_select. При отсутствии поддержки система выдаст исключение в runtime — CX_SY_SQL_UNSUPPORTED_FEATURE.
Разберём текущие особенности использования этих сценариев.
Основным предназначением данного синтаксиса безусловно является использование внутренней таблицы и JOIN её данных с данными в СУБД. По сути это еще одна альтернатива FOR ALL ENTRIES, но без тех ограничений что есть в FAE.
Использовать этот синтаксис как замену операций READ TABLE и LOOP в первом сценарии допустимо, но как правило выполняться это будет медленнее. Говоря о первом сценарии следует упомянуть что условия, по которым система решает следует ли переносить таблицу на уровень СУБД аналогичны тем условиям, что используются для определения необходимости обращения к СУБД при использовании буферизированных таблиц. Таким образом таблица будет переносится на уровень СУБД если:
- Используются агрегатные функции,
- Используется DISTINCT,
- Используются JOIN-ы,
- Используется WITH,
- Используются SQL выражения не из списка совместимых,
- Множество других ограничений…
Убедиться в том что таблица переносится в СУБД можно посмотрев трассировку запроса, выглядеть это будет примерно следующим образом: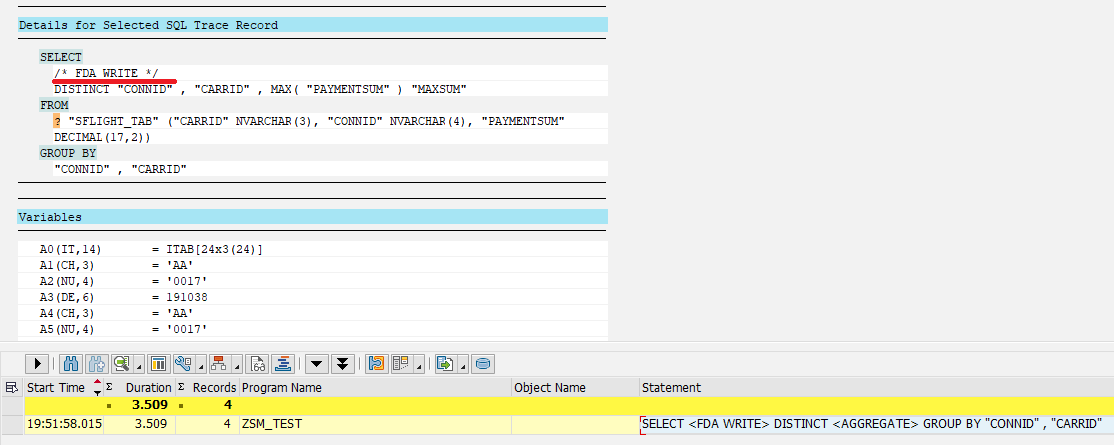
Есть ряд особенностей SQL запросов с внутренней таблицей как источником данных:
- Нельзя указать более одной таблицы в SQL запросе, JOIN двух внутренних таблиц сделать не выйдет. Нельзя использовать одну и ту же таблицу в запросе несколько раз, например с дополнением WITH.
- Обязательно требуется указание псевдонима для внутренней таблицы через дополнение AS.
- Тип строки таблицы может быть как элементарным, так и структурным:
- Если строка элементарного типа, обращаться к столбцу этой таблицы можно через table_line. В списке полей для table_line можно задать псевдоним через AS. Тип таблицы в данном случае не может быть строкой (допустимо использование строк ссылающихся на словарный тип SSTRING) или ссылочным типом.
- Если строка структурного типа, недопустимо обращение в SQL запросе к полям являющимися вложенными структурами, строками или таблицами.
- Если используется дополнение ORDER BY PRIMARY KEY во внутренней таблице обязательно должен быть указан primary key.
- Нельзя при статическом указании таблицы во FROM использовать обобщённые типы таблиц (вроде INDEX TABLE). Обобщённые типы могут быть использованы при динамическом FROM. Пример:
123456789101112131415161718192021CLASS lcl_test DEFINITION.PUBLIC SECTION.CLASS-METHODS:start,test IMPORTING it_table TYPE INDEX TABLE.ENDCLASS.CLASS lcl_test IMPLEMENTATION.METHOD test.DATA:lt_keys TYPE STANDARD TABLE OF sflight.SELECT connid, price, carridFROM ('@it_table') AS sflight_tabINTO CORRESPONDING FIELDS OF TABLE @lt_keys.cl_demo_output=>display( lt_keys ).ENDMETHOD.ENDCLASS. - Внутренняя таблица не может содержать столбцов со ссылкой на устаревшие типы данных: DF16_SCL и DF34_SCL.
- Если внутренняя таблица имеет элементарный тип, при использовании CTE, после WITH нельзя указывать поля через * или data_source~*.
- Для внутренней таблицы необходимо указывать primary key явным образом, при использовании стандартного ключа (with default key) система выдаст предупреждение.
Даже если таблица не будет перенесена на уровень СУБД, данные в ней обрабатываются так как же как и в СУБД:
- Строки со ссылкой на SSTRING обрабатываются как строки с фиксированной длинной и игнорированием завершающих пробелов.
- SQL выражения работают таким же образом, как если бы они работали на уровне СУБД:
- DIV и MOD могут выдавать отличные от аналогичных в ABAP результаты
- Обработка NULL значений аналогична тому как это работает в SQL запросах.
- Таблица всегда рассматривается как независимая от манданта.
Примеры
Следующий пример демонстрирует типичный случай использования внутренних таблиц как источника данных, а именно перенос таблицы на уровень СУБД и выполнение JOIN:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DATA lt_itab TYPE HASHED TABLE OF scarr WITH UNIQUE KEY mandt carrid. IF NOT cl_abap_dbfeatures=>use_features( EXPORTING requested_features = VALUE #( ( cl_abap_dbfeatures=>itabs_in_from_clause ) ) ). cl_demo_output=>display( `Система не поддерживает внутренние таблицы как источник данных` ). RETURN. ENDIF. lt_itab = VALUE #( ( carrid = 'LH' carrname = 'L.H.' ) ( carrid = 'UA' carrname = 'U.A.' ) ). SELECT scarr~carrid, scarr~carrname, spfli~connid FROM @lt_itab AS scarr INNER JOIN spfli ON scarr~carrid = spfli~carrid INTO TABLE @DATA(lt_result) ##db_feature_mode[itabs_in_from_clause] ##itab_db_select. |
Пример в котором не происходит обращения к СУБД:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
TYPES: BEGIN OF ts_line, id TYPE c LENGTH 1, number TYPE i, END OF ts_line. DATA lt_itab TYPE HASHED TABLE OF ts_line WITH UNIQUE KEY id. DATA(lo_rnd) = cl_abap_random_int=>create( seed = CONV i( sy-uzeit ) min = 1 max = 100 ). lt_itab = VALUE #( FOR i = 1 UNTIL i > 25 ( id = substring( val = sy-abcde off = i len = 1 ) number = lo_rnd->get_next( ) ) ). SELECT * FROM @lt_itab AS numbers WHERE number > 50 ORDER BY id INTO TABLE @DATA(lt_result) ##db_feature_mode[itabs_in_from_clause] ##itab_db_select. cl_demo_output=>display( lt_result ). |
Формирование результата элементарного типа (lt_result1) и структурного (lt_result2):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
DATA lt_itab TYPE SORTED TABLE OF i WITH UNIQUE KEY table_line. lt_itab = VALUE #( ( 1 ) ( 2 ) ( 3 ) ). DATA lt_result1 LIKE lt_itab. SELECT table_line FROM @lt_itab AS numbers INTO TABLE @lt_result1. cl_demo_output=>write( lt_result1 ). SELECT table_line AS number FROM @lt_itab AS numbers INTO TABLE @DATA(lt_result2). cl_demo_output=>display( lt_result2 ). |
Производительность
Если сравнивать скорость выполнения FAE с FDA и JOIN с внутренней таблицей, скорость работы практически не отличается, оба сценария выигрывают у сценария переноса внутренней таблицы через AMDP.
Итого
Подводя итоги, данный механизм выглядит вполне привлекательной заменой использования запросов с FOR ALL ENTRIES, если сравнивать с точки зрения накладываемых в обоих случаях ограничений и безопасности в части необходимости доп. проверок в коде при использовании FAE.
Спасибо за статью.
Если нужно сделать агрегацию внутренней таблицы то агрегация через передачу во временную таблицу на БД тоже будет работать медленней чем через loop/collect?
Например таблица 100к записей, которая становится 5к после агрегации.