 Виртуальная сортировка внутренних таблиц, добавленная в ABAP 7.52, описана всего одним методом — virtual_sort, класса CL_ABAP_ITAB_UTILITIES
Виртуальная сортировка внутренних таблиц, добавленная в ABAP 7.52, описана всего одним методом — virtual_sort, класса CL_ABAP_ITAB_UTILITIES
Основная особенность виртуальной сортировки заключается в том, что вы получаете массив индексов относительно сортировки, без необходимости формирования копии таблицы (или её изменения).
Далее разберём особенности работы метода на простых примерах.
Результат виртуальной сортировки можно использовать для формирования копии таблицы с новым порядком сортировки, на основе полученных индексов:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
TYPES: BEGIN OF ty_common_type, a TYPE i, b TYPE i, END OF ty_common_type. DATA: lt_table_one TYPE SORTED TABLE OF ty_common_type WITH UNIQUE KEY a, lt_table_two TYPE STANDARD TABLE OF ty_common_type. " Таблица с сортировкой по полю а ASC lt_table_one = VALUE #( ( a = 2 b = 2 ) ( a = 1 b = 3 ) ( a = 3 b = 1 ) ). " Таблица с сортировкой по полю b ASC lt_table_two = VALUE #( FOR index IN cl_abap_itab_utilities=>virtual_sort( im_virtual_source = VALUE #( ( source = REF #( lt_table_one ) components = VALUE #( ( name = 'b' ) ) ) ) ) ( lt_table_one[ index ] ) ). cl_demo_output=>write( lt_table_one ). cl_demo_output=>display( lt_table_two ). |
Внимательный читатель сразу задаст вопрос, а зачем нам пользоваться этим методом, если мы можем выполнить нечто подобное?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... DATA: lt_table_one TYPE SORTED TABLE OF ty_common_type WITH UNIQUE KEY a, " Создадим новый тип таблицы с нужным нам ключевым полем lt_table_two TYPE SORTED TABLE OF ty_common_type WITH UNIQUE KEY b. lt_table_one = VALUE #( ( a = 2 b = 2 ) ( a = 1 b = 3 ) ( a = 3 b = 1 ) ). lt_table_two = lt_table_one. ... |
Результат:

И безусловно будет прав, в подобных случаях нам не потребуется использовать метод виртуальной сортировки, ABAP окружение сделает все само. Но что если таблица не сортированная, а стандартная и порядок сортировки не соответствует порядку сортировки ключа (по возрастанию)?
Читатель может вновь возразить и сказать что может сделать вот так:
|
1 2 3 4 5 6 7 8 9 10 |
... DATA: lt_table_one TYPE SORTED TABLE OF ty_common_type WITH UNIQUE KEY a, " Определим стандартную таблицу lt_table_two TYPE STANDARD TABLE OF ty_common_type. ... lt_table_two = lt_table_one. " Выполним явную сортировку, но уже по убыванию SORT lt_table_two BY b DESCENDING. ... |
И вновь будет прав, более того, скорость виртуальной сортировки на большом объеме данных с формированием копии таблицы будет ниже:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS main. ENDCLASS. CLASS demo IMPLEMENTATION. METHOD main. TYPES: BEGIN OF ty_line, col1 TYPE i, col2 TYPE i, END OF ty_line, tt_itab TYPE STANDARD TABLE OF ty_line WITH EMPTY KEY. DATA: lt_sorted_tab_one TYPE tt_itab, lt_sorted_tab_two LIKE lt_sorted_tab_one. DATA: lv_start_time TYPE timestampl, lv_end_time TYPE timestampl, lv_diff TYPE timestampl. DATA(lo_rnd) = cl_abap_random_int=>create( seed = + sy-uzeit min = 1 max = 1000 ). DATA(lt_itab) = VALUE tt_itab( FOR i = 1 UNTIL i > 10000000 ( col1 = lo_rnd->get_next( ) col2 = lo_rnd->get_next( ) ) ). GET TIME STAMP FIELD lv_start_time. lt_sorted_tab_two = lt_itab. SORT lt_sorted_tab_two BY col1 DESCENDING col2 ASCENDING. GET TIME STAMP FIELD lv_end_time. lv_diff = lv_end_time - lv_start_time. WRITE: /(50) 'Явная сортировка: ', lv_diff. GET TIME STAMP FIELD lv_start_time. lt_sorted_tab_one = VALUE #( FOR idx IN cl_abap_itab_utilities=>virtual_sort( im_virtual_source = VALUE #( ( source = REF #( lt_itab ) components = VALUE #( ( name = 'col1' descending = abap_true ) ( name = 'col2' ) ) ) ) ) ( lt_itab[ idx ] ) ). GET TIME STAMP FIELD lv_end_time. lv_diff = lv_end_time - lv_start_time. WRITE: /(50) 'Виртуальная сортировка: ', lv_diff. ASSERT lt_sorted_tab_one = lt_sorted_tab_two. ENDMETHOD. ENDCLASS. START-OF-SELECTION. demo=>main( ). |
Результат:

Так зачем вообще нужно использовать виртуальную сортировку?
Основная суть её в следующем:
- Результат виртуальной сортировки — таблица с индексами (тип cl_abap_itab_utilities=>virtual_sort_index), в некоторых случаях могут потребоваться только индексы, например: если нужно убедиться в изменении сортировки некоторого массива данных, копирование данных в таком случае будет слишком затратной по памяти операцией. Подобный случай используется во внутреннем устройстве ALV;
- Результат виртуальной сортировки или последующую сформированную таблицу можно передавать в выражения без создания вспомогательных переменных или методов;
- Результат виртуальной сортировки можно дополнительно фильтровать с учётом входной таблицы индексов — параметр im_filter_index (тип cl_abap_itab_utilities=>virtual_sort_index);
- Позволяет получать результат сортировки относительно нескольких таблиц, объединяя их в виртуальном массиве;
Третий вариант использования можно рассмотреть на примере:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
... DATA(lt_index_filter) = VALUE cl_abap_itab_utilities=>virtual_sort_index( FOR <ls> IN lt_itab INDEX INTO idx WHERE ( col1 >= 500 ) ( idx ) ). lt_sorted_tab_one = VALUE #( FOR idx IN cl_abap_itab_utilities=>virtual_sort( im_virtual_source = VALUE #( ( source = REF #( lt_itab ) components = VALUE #( ( name = 'col1' descending = abap_true ) ( name = 'col2' ) ) ) ) im_filter_index = lt_index_filter ) ( lt_itab[ idx ] ) ). ... |
Таким образом мы можем оценить изменение сортировки в определённой группе индексов, построенной по условию фильтрации.
Четвёртый вариант использования еще более хитрый (из официальной документации):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS main. ENDCLASS. CLASS demo IMPLEMENTATION. METHOD main. TYPES: BEGIN OF line1, col1 TYPE i, col2 TYPE i, END OF line1, itab1 TYPE STANDARD TABLE OF line1 WITH EMPTY KEY, BEGIN OF line2, col1 TYPE string, col2 TYPE string, END OF line2, itab2 TYPE STANDARD TABLE OF line2 WITH EMPTY KEY. TYPES: BEGIN OF test_line, col11 TYPE i, col12 TYPE i, col21 TYPE string, col22 TYPE string, END OF test_line, test_tab TYPE STANDARD TABLE OF test_line WITH EMPTY KEY. DATA(rnd) = cl_abap_random_int=>create( seed = + sy-uzeit min = 0 max = 1 ). DATA(itab1) = VALUE itab1( FOR i = 1 UNTIL i > 10 ( col1 = rnd->get_next( ) col2 = rnd->get_next( ) ) ). DATA(itab2) = VALUE itab2( FOR i = 1 UNTIL i > 10 ( col1 = cond #( when rnd->get_next( ) = 0 THEN `X` ELSE `Y` ) col2 = cond #( when rnd->get_next( ) = 0 THEN `X` ELSE `Y` ) ) ). DATA(out) = cl_demo_output=>new( ). out->write( itab1 )->write( itab2 ). out->next_section( `Virtual Sort of Combined Tables` )->begin_section( `itab1 by col1, col2, Ascending` )->next_section( `itab2 by col1, col2, Descending` ). DATA(v_index) = cl_abap_itab_utilities=>virtual_sort( im_virtual_source = VALUE #( ( source = REF #( itab1 ) components = VALUE #( ( name = 'col1' ) ( name = 'col2' ) ) ) ( source = REF #( itab2 ) components = VALUE #( ( name = 'col1' astext = abap_true descending = abap_true ) ( name = 'col2' astext = abap_true descending = abap_true ) ) ) ) ). out->write( v_index ). DATA sorted_tab1 TYPE itab1. sorted_tab1 = VALUE #( FOR idx IN v_index ( itab1[ idx ] ) ). DATA sorted_tab2 TYPE itab2. sorted_tab2 = VALUE #( FOR idx IN v_index ( itab2[ idx ] ) ). DATA(comb_tab) = VALUE test_tab( FOR i = 1 UNTIL i > 10 ( col11 = sorted_tab1[ i ]-col1 col12 = sorted_tab1[ i ]-col2 col21 = sorted_tab2[ i ]-col1 col22 = sorted_tab2[ i ]-col2 ) ). DATA(test_tab) = VALUE test_tab( FOR i = 1 UNTIL i > 10 ( col11 = itab1[ i ]-col1 col12 = itab1[ i ]-col2 col21 = itab2[ i ]-col1 col22 = itab2[ i ]-col2 ) ). SORT test_tab STABLE BY col11 col12 col21 DESCENDING AS TEXT col22 DESCENDING AS TEXT. ASSERT comb_tab = test_tab. out->write( comb_tab ). out->display( ). ENDMETHOD. ENDCLASS. START-OF-SELECTION. demo=>main( ). |
Результат:
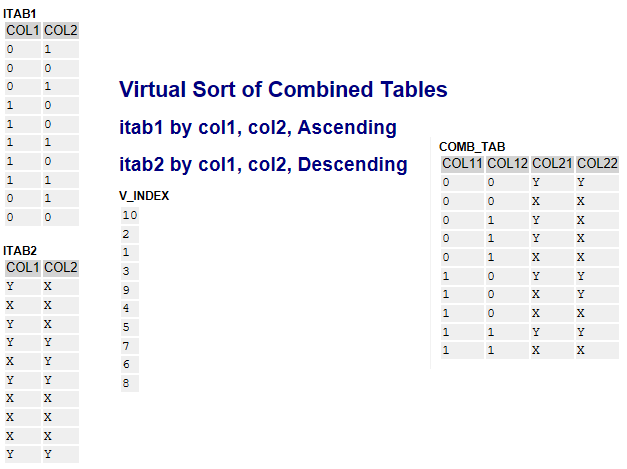
Представьте что вы объединяете две таблицы itab1 и itab2 в некоторый комбинированный массив данных и сортируете его на основе двух полей из itab1 по возрастанию и двух полей в itab2 по убыванию. Именно такой массив сортированных индексов будет сформирован на выходе.
При комбинированном подходе требуется иметь одинаковое число строк в таблицах, иначе получите дамп — ITAB_VSORT_ILLEGAL_TABLE.
Комбинированный подход уже будет выигрывать как по памяти, так и по скорости, при большом объеме данных, т.к. не требует явного создания массива данных для сортировки, как при явном объединении с последующей явной сортировкой.